Alignment by Mistake: Cognitive Biases in Humans and LLMs

What It Means When Machines Make the Same Mistakes We Do
The Model and the Situation
When people talk about LLMs, the question of AGI is generally not far behind. With each new release from Anthropic or OpenAI we wonder: are we getting closer? The discussion is no longer confined to machine learning labs or military think tanks — it's gone mainstream.
In this context, the mistakes made by LLMs — hallucinations, misinterpretations, or inconsistent reasoning — are often taken as a gap between humans and machines. Proof that models like ChatGPT don’t think like us, and perhaps never will.
Recent work by Anthropic, especially efforts to trace the “thought processes” of models like Claude, has shown that LLMs often make mistakes that resemble human cognitive biases. The thing is, we’re notoriously bad at identifying our own biases — so it might be even harder to recognize them in something that mimics us. That may be why we have failed to consider these errors as potential signs of similarity, rather than difference.
Anthropic’s latest paper, “On the biology of large language models” explores the inner dynamics of LLMs, revealing surprising complexity — and some unexpected echoes of human cognition. It reminded me of another kind of investigation: “The Person and the Situation”, a book published in the 1990s, used social psychology experiments to show how environment and context shape human thinking. In their own way, the authors Ross and Nesbitt were, like Anthropic, engaged in a kind of reverse engineering. Only instead of a model, the system under scrutiny was the human mind. And maybe their results suggest something uncomfortable: that we are a little more like LLMs than we’d care to admit.
What does it mean if we hallucinate in ways that mimic an LLMs? Or what about if our own chains of thought are just as error prone? Can both humans and LLMs be primed by context to draw flawed conclusions? These parallels might not tell us as much as about how LLMs really think — but they might force us to reflect on the reliability of our own thought process. Maybe Human General Intelligence isn’t as clean, consistent or definable as we may like to believe.
Humans Conform and LLMs are Unfaithful
One of the key points of The Person and the Situation is that we overestimate personality traits as predictors of behaviour. In reality, situational factors — like the pressure to conform — can influence our decisions in ways we might never imagine. The authors illustrate this with a series of classic experiments by social psychologist Solomon Asch, designed to measure people's trust in their own judgement.
The task was deliberately simple. Participants were shown a line and asked to identify which of three comparison lines were most similar in length. The simplicity was intentional — it was meant to make the correct answer obvious, and to ensure participants had every reason to trust their own judgements.
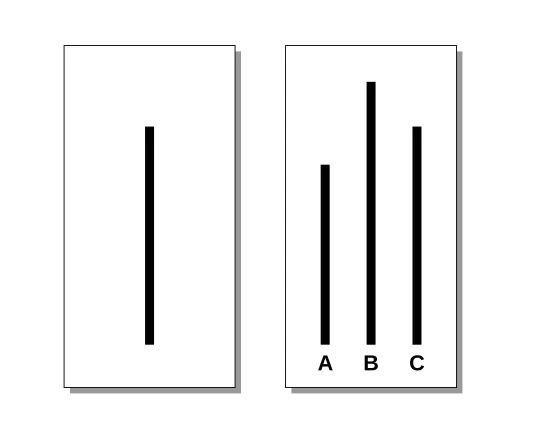
Groups consisted of 7–9 people, but with a twist: all but one were actors. In the first few rounds, everyone gave the correct answer — as expected, given how straightforward the task was. But in later rounds, the actors began to unanimously choose deliberately incorrect answers1. The real participant — placed last in the response order — watched, often visibly confused, as each person ahead of them chose the wrong line.
And in a surprising number of cases, participants followed the group. Overall, 74% of participants gave at least one incorrect answer and conformity occurred in more than a third of all trials2 — despite the task remaining as easy in all cases. For comparison, in control trials with no group pressure, the error rate was close to 0.7%.
What does this have to do with LLMs?
In some ways we can think of this as a form of distorted chain-of-thought reasoning.The task is clear. The goal is known. The process is simple: look at the chart, identify the target line and pick the closest matching one. But when faced with unanimous disagreement from others, the participant’s internal reasoning starts to bend toward the group. They re-interpret the evidence, reverse-engineer a justification for the group's choice, and override their own perception.
Anthropic recently documented something remarkably similar in their work on chain-of-thought “unfaithfulness”. In one case Claude was asked to solve a simple math problem — but the prompt also included a suggested (but incorrect) answer from a human user.
As with the Asch study, the suggested answer is wrong. And like the human participant, the LLM seems to feel pressure to reason backward toward the answer, rather than solving the problem from first principles.
As Anthropic describes it, “we can see that Claude works backwards from the human-suggested answer to infer what intermediate output would lead to that answer. Its output depends on the suggested answer ‘4’ from the hint in the prompt, and the knowledge that it will next multiply this intermediate output by 53”3.
In both cases, human and model, the agent adjusts its reasoning not because the task itself changed, but because someone else suggested an alternative answer. And crucially, there was no obvious reason to distrust the suggestion. The influence didn’t come from threat or reward, but from the subtle authority or perceived consensus.
Variations of the Asch experiment have been run where participants were told that there was a higher monetary reward for a correct answer when everyone did not guess the same answer. In these cases conformity rates dropped significantly — suggesting that when people had a reason to expect that the group might be wrong, they were more likely to trust their own judgement.
In Anthropic’s case the model didn’t have access to a calculator, but it didn’t question the suggestion or check the math. Running similar tests on models that do have access to calculators, however, showed they were still likely to follow the incorrect suggestion. It seems the pressure to conform — or to cooperate with a given answer — is something both humans and LLMs are surprisingly susceptible to.
Humans Construe, LLMs Hallucinate
In social psychology, construal refers to how we interpret the world around us— especially how we perceive the situations and the actions of others. In the Person and the Situation, the authors argue that most people fail to appreciate just how much our own behaviour is shaped by this internal act of interpretation.
Specifically, they highlight three key errors people make about construal:
We believe we passively represent the world, but perception is actually an active process. We construct representations of the world based on limited inputs. In this way , we might say that the LLMs behave similarly — responding not just to the input data, but by generating internal representations based on prior patterns.
We assume others see situations the same way we do, but in fact there is significant variance in how different people interpret the same event. Even our own interpretations shift depending on mood, context, or framing.
We over-attribute errors to individuals and under-attribute them to context. As the authors put it: “people are too quick to ‘recompute’ the person and too slow to recompute or reconstrue the situation”4. In other words, we tend to blame mistakes on personality (“they’re careless”) rather than context (“the task was misleading” or “the situation was new and unusual”). Perhaps we do the same with LLMs: when a model makes an error, we’re quick to say “it’s not thinking like a human!” — but slow to ask whether it was simply responding to ambiguous or biased input.
To show how easily construal can shift, the authors describe a clever experiment involving professional rankings. Participants were told they’d be asked to rank various professions—nothing unusual. But just before giving their answers, one group was told that previous participants had ranked politicians highly, while another group was told politicians were ranked near the bottom.

The results were striking. Despite never meeting the other participants, and despite having stable-seeming concepts of what a “politician” is, each group’s rankings were dramatically influenced by the framing they received. But here’s the key insight: the framing didn’t change their opinions—it changed their mental representation.
The groups who were informed that politicians were rated highly by previous groups brought to mind positive examples (Jefferson, Washington). Those told politicians were rated poorly imagined corrupt or cynical figures. The same term—“politician”—meant very different things depending on the prompt. That’s construal in action.
In Anthropic’s research, we see a similar effect in how LLMs hallucinate. Models like Claude are trained not to answer questions when they don’t know the answer. And yet, in one example, the model was asked about a paper and—incorrectly—attributed it to Andrej Karpathy, a well-known machine learning researcher.
In other cases, the model correctly responded with “I don’t know” or avoided guessing. But in this instance, it hallucinated. Why? Because Karpathy is strongly associated with deep learning, and the paper was about deep learning. The connection wasn’t random—it was a pattern-completion based on associative construal.
We can see this as similar to the “politician” construal example. In both cases the outcome was influenced by the construal process. In the human case the “prompt” was the other group rankings and this brought to mind the positive or negative associations and resulted in the change in their own ranking. In the LLM example Karpathy association “brought to mind” deep learning and caused the model to output a famous deep learning paper.
At first glance, we might look at this kind of hallucination and say: “That’s why LLMs will never be AGI.” Or, “That’s nothing like how humans think.” But when we look at how we ourselves reason—how easily we’re swayed by framing, priming, and social cues—the difference starts to blur.
If hallucination is a sign of cognitive failure, it might not just be the machines we’re diagnosing.
The Model and the Person
We began by asking questions about AGI. But maybe the deeper issue is that we don’t fully understand our own GI. As The Person and the Situation reminds us, humans are far less rational, consistent, and internally coherent than we like to believe. We don’t operate according to fixed personality traits. Instead, our behavior is shaped by shifting environments, social pressures, and subjective interpretations—by situations, not just selves.
These insights should give us pause when we demand consistency, self-awareness, or truth from language models. If humans don’t live up to those standards, why do we expect LLMs to?
What’s more, the fact that LLMs make mistakes that resemble our own cognitive biases is not necessarily a flaw—it might be a mirror. These systems offer a strange new lens on reasoning itself, and in some cases, they replicate not just the outputs of human thought, but its vulnerabilities, shortcuts, and blind spots.
Maybe that's the real surprise: not that LLMs are still so different from us, but that—when they go wrong—they sometimes go wrong in exactly the same ways.
And if that’s true, then perhaps alignment isn’t something we impose on machines. Maybe it’s something we uncover, slowly, by mistake.
References
1. Asch conformity experiments , Wikipedia.
2. Ross, L., and Nisbett, R. E. (1991). The Person and the Situation: Perspectives of Social Psychology, p. 31.
3. Anthropic (2025). Chain-of-thought Faithfulness , in The Biology of Large Language Models.
4. Ross, L., and Nisbett, R. E. (1991). The Person and the Situation: Perspectives of Social Psychology, p. 13.
An earlier version of this essay appeared on Substack .


