Layers of Meaning: How Detokenization and Abstraction Impact Prompt Design

What Prompting Looks Like Inside an LLM and What We Can Learn From a Few Real Examples
If you’ve ever used an LLM like ChatGPT or Claude, you’ve probably spent time thinking about how to write a good prompt. It might be as simple as asking a factual question like “What’s the capital of Ireland?”, or as creative as asking the model to pretend it’s Mount Everest giving a geology lecture. Whatever the form, prompting feels intuitive: you say what you want, and the model responds. But Anthropic’s recent research, especially in The Biology of Large Language Models1, suggests something surprising - the apparent simplicity of prompting masks a far more complex inner world.
This latest research builds on earlier work - such as Anthropic’s own Circuits paper2 and other research like Finding Neurons in a Haystack3 - which maps how prompts are processed from input to output. Inside a transformer, a prompt doesn't just go in one end and come out the other. It flows through dozens of layers, and each layer transforms it in a different way. The early layers interpret tokens in a shallow, local sense. The later layers prepare final outputs. But the real conceptual magic, the stuff that resembles reasoning, understanding, and abstraction, happens in the middle.
In this post, we’ll explore what the early and middle layers of a model are actually doing, and what this reveals about how prompting works (and sometimes doesn’t). We’ll look at how early layers act like sensory neurons, doing detokenization, combining subword pieces and detecting simple local patterns. Then we’ll look at the middle layers, where models represent more abstract, global concepts like “spatial direction”, “trade and commerce,” or “error reporting”. Features that feel more semantic than syntactic.
We’ll focus specifically on these early and middle stages, because this is where prompting appears to have the most influence. By the time your prompt reaches the later layers, the model is typically translating its internal representations into output tokens — a process sometimes called retokenization4. These final layers are crucial for generating fluent language, and while they likely do contribute to shaping outputs, they seem more concerned with how ideas are expressed than what those ideas are. That distinction isn’t absolute, and future research may blur these boundaries, but for this post, we’ll focus on the early and middle layers, where most of the conceptual groundwork appears to happen.
Understanding the early-to-middle layer pipeline helps clarify both the power and the limits of prompting. It shows why simple word swaps can change behaviour, why models sometimes misinterpret instructions, and why you may not always get what you thought you asked for.
And maybe most intriguingly, it shows that prompting is less like programming and more like persuasion, not issuing orders, but nudging a deeply complex system in the general direction you want it to go.
The Pseudo-Language of Detokenizaton
Before your prompt can be processed by a large language model, it first needs to be translated into a format the model can understand. This translation step is called tokenization. It breaks text into smaller units - or subwords - called tokens, which serve as the model’s input vocabulary.
This process allows the model to cover a large vocabulary using a much smaller fixed set of building blocks. For instance, BPE (Byte Pair Encoding) tokenizers, like the one used in GPT-2, typically use around 50,000 tokens to represent hundreds of thousands of possible words and word fragments. More recent models like GPT-4 use even more advanced tokenizers (such as tiktoken) that optimize token splitting for speed and coverage.
We won’t go into much detail about tokenizers here since they are a field of research in their own right. If you’re curious, you can check out this post or explore the tiktoken tokenizer used in newer transformer models like GPT-4.
The key idea to take away is this: tokenization is a separate process from the model itself, and while it's efficient, it isn’t always semantically consistent.
Take the word Harvard. You might expect that it always gets the same tokens, but that's not true. Depending on where it appears in a sentence:
- At the start of a sentence: 'Ha', '##vard'
- Elsewhere in a sentence: 'Harvard'
It’s sometimes one token, sometimes two, even though the meaning hasn’t changed. This isn’t an isolated case. Tokenization introduces many such quirks.
So how does the model make sense of this noisy, inconsistent input?
Enter the Early Layers
It turns out that the early layers of LLMs spend a surprising amount of time undoing the tokenizer’s work. This process is sometimes called detokenization - reconstructing meaningful units (like "Eiffel Tower") from raw fragments like 'E', '##iff', '##el'.
For example, the input:
“The Eiffel Tower is in…”
might be tokenized as:
['The', 'E', '##iff', '##el', 'Tower', 'is', 'in']
But the model doesn’t really “know” anything about 'E' or '##iff'. What it likely does know is something about “Eiffel Tower”, that it's a monument, that it's in France, etc. So the model must reconstruct that concept from fragmented pieces before it can reason about it or respond intelligently.
This is where early layer features come in: they detect and reassemble these broken subwords into coherent concepts. Often in the form of n-gram associations, like “Eiffel Tower” or “Harvard University.”
This process of reconstructing token fragments into coherent concepts can be thought of as building a kind of pseudo-vocabulary. And some researchers believe it is one of the main functions of these early layers. An earlier paper5 attempting to understand how higher level human concepts were represented internally in LLMs noted that “... this computational motif—merging individual tokens into more semantically meaningful n-grams in the pseudo-vocabulary via a linear combination of massively polysemantic neurons—is one of the primary function of early layers.”
Where’s my order?
To better understand what’s happening inside these layers, we can turn to some of the randomly sampled features Anthropic has published from models like Haiku. Specifically, in the Circuit Tracing paper, Anthropic examined “50 randomly sampled features from assorted layers of each model.”
By looking at a few of these features from the early and middle layers, we can get a clearer picture of how our prompts are processed as they pass through the model - and how meaning starts to emerge inside the network.
To start with, this is an example of a feature Anthropic found in the first layer of the Haiku model.
Note that with all the following images you should look at them in the Anthropic paper to be able to interact with them by hovering over different features and scrolling down to see a range of options which are not shown in the screenshots here.

What is going on here? This is the visualization Anthropic uses to show what text strongly activates a particular feature - or a conceptual neuron. In this case, in the early layer, the model fires when it sees the word “order”. Specifically, it seems to fire when it sees the word order in contexts related to food and restaurant orders.
While the model may not have to do explicit detokenization here — “order” is a single token — it does do low level context matching to identify that this order is related to food and restaurants. It is not the general concept of an order such as “these books are out of order”, “the natural order of things”, or a “military order”. Instead its similar to what you would see with a simple n-gram type program which identifies commonly co-occurring words, e.g. “my order”, “your order” or “take my order”.
An example in the above feature is someone ordering “Chicken nuggets”, “veal steaks” and “Eggs Benedict”. These words have different subword tokenization so early layers of this LLM might be simply recombining those subword elements in common n-gram combinations that it knows will be useful since they frequently occur.
How many is too many?
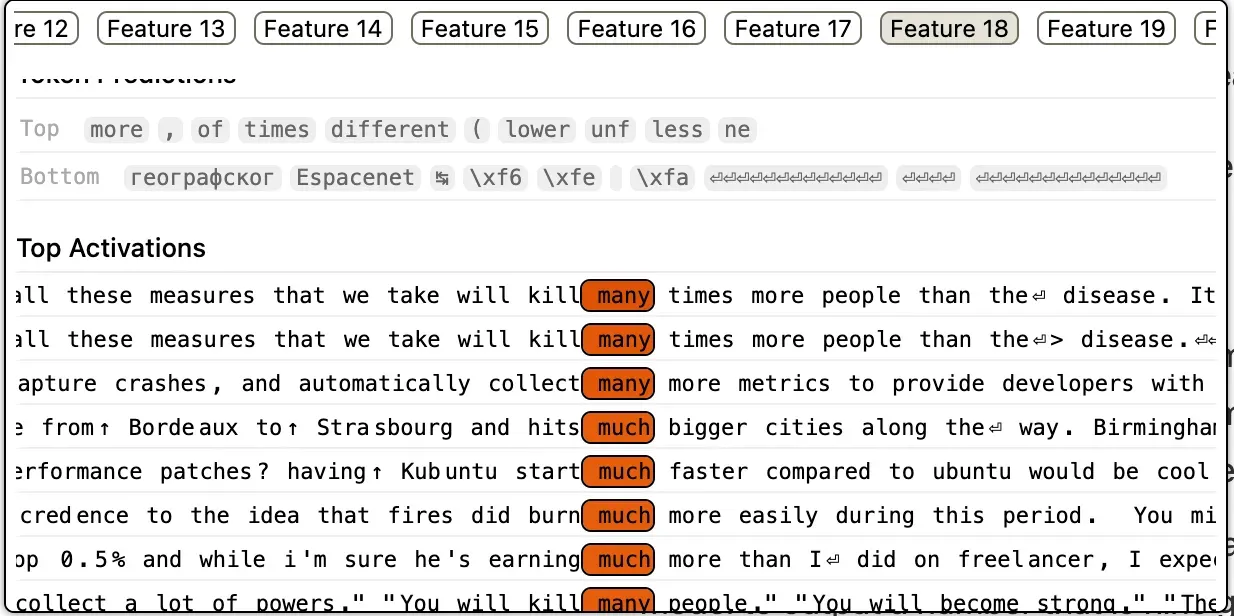
This is another feature from the first layer of the model. We can see here that this is a very low level, simple feature and it is related to comparison and quantity. Again, its a simple n-gram-like identification of common co-occurring patterns — “many people”, “start much faster”, “collect many more metrics”.
You can think of this feature like a simple function which detects that the input is referring to a comparison or quantity, especially involving size, amount or degree. Its not an abstract understanding of whether its related to numbers or size. Instead its just identifying the local aspect of its semantic meaning.
Almost a Place
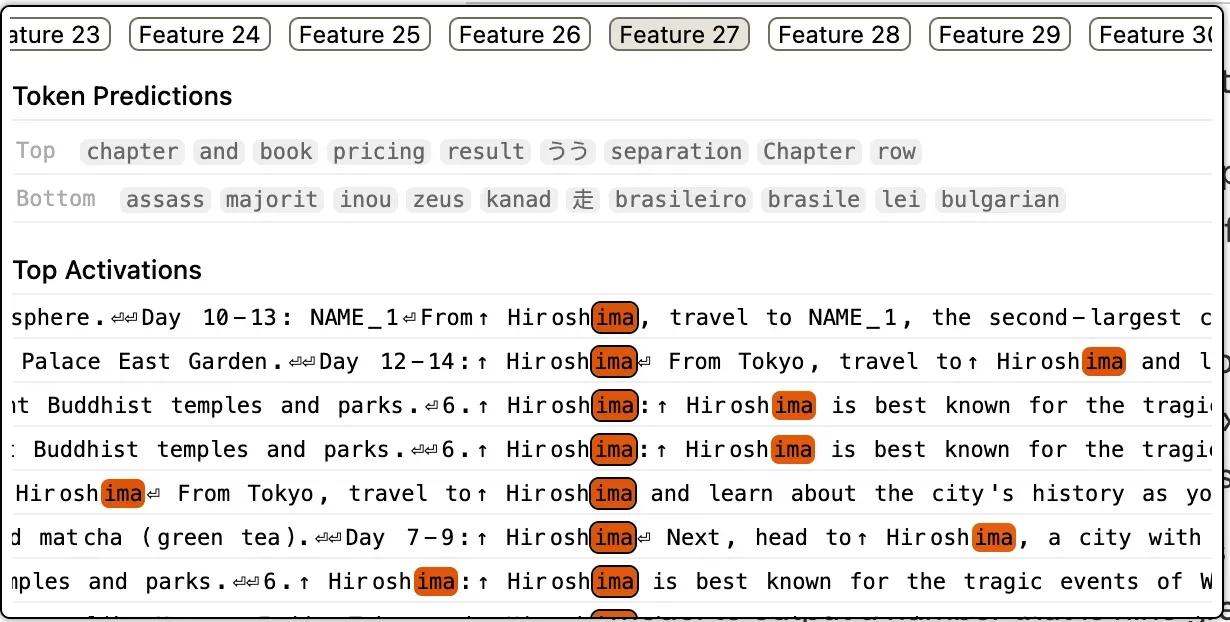
In the above feature on the first layer we can see an example of early or partial detokenization. The “ima” part of “Hiroshima” is being associated with the city in Japan as a tourist and historical site. It may recombine the whole world in later layers as a common feature to strengthen the association. Alternatively, “ima” could represent a common and frequently occurring subword part in its own right and associate “ima” with a placename in Japan. In either case it is still doing a relatively simple, n-gram-like matching task to identify some semantic meaning to pass up to later layers.
Detokenization in practice
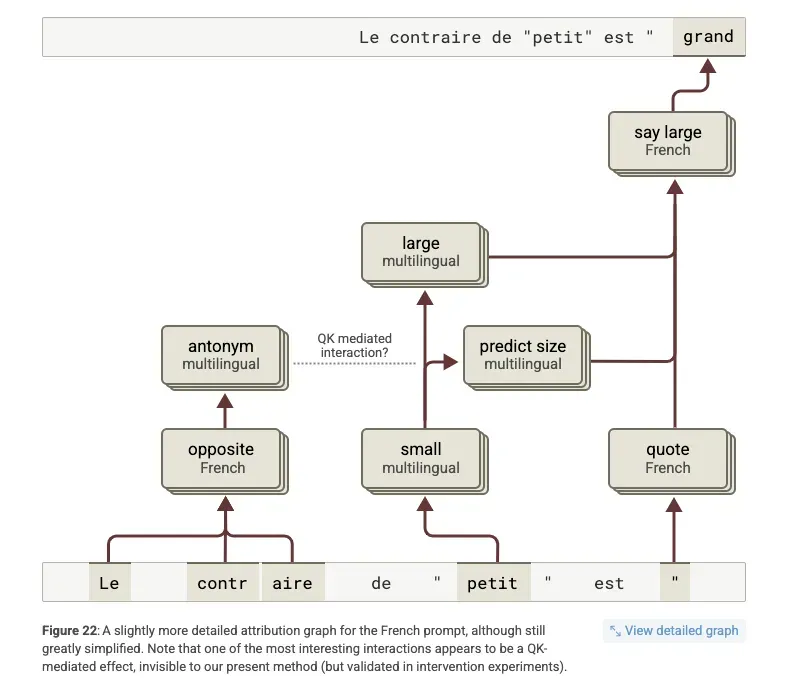
The multilingual example Anthropic shared in their paper includes a good example of the benefits of detokenization in a practical use case. The researchers are trying to understand how LLMs represent multilingual inputs and one of the prompts is a French sentence — “Le contraire de "petit" est ” — which means “the opposite of small is “. The goal is to try and understand what features are activated and how the model represents difference languages to generate an output.
You can see that the model does use some multilingual representations in the circuit along with some French representations to identify the correct output, which is “grand” or “large”. You can see from the graph that the initial tokenization of “contraire” is “contr” and “##aire”. Remember, tokenization is, for want of a better word, a hack. It is an attempt to use the smallest amount of subword tokens to create the largest amount of whole words.
“Contraire” does not seem to occur frequently enough in the tokenizer training data to warrant being represented via a single word token. However, in the early layers of the LLM, via the context of the input, are able to identify that these two tokens are referring to the concept of “opposite” in French. This concept, however, seems to be associated with the word “contraire” and not the separate tokens.
This could be due to the MLP layers acting as a key-value lookup where the word “contraire” activates for the idea of “opposite in French”. As a result the early layers of the LLM undo or detokenize the multiple tokens of “contr” and “##aire” to create a single word: “contraire”. You can see this in the diagram below which shows the representations where “contraire” is combined.
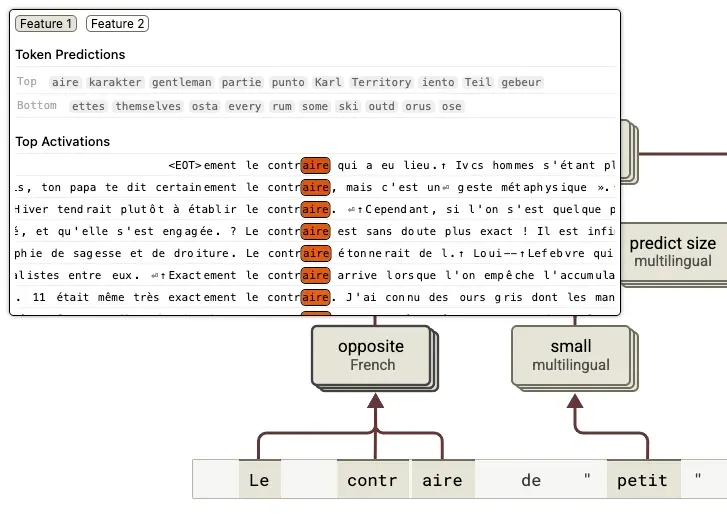
We can see that the two subwords are now represented by a single word which enables the model to link to the multilingual concept of antonym. Or as Anthropic note:
“Beyond this, it's interesting to note several things. We can see the multi-token word "contraire" being "detokenized" to activate abstract multilingual features.”
This is evidence that the model is internally reconstructing meaningful concepts from token fragments. This enables LLMs to reason about abstract words and ideas and not just simple strings or token fragments which might lack higher level semantic meaning. “Contraire” is detokenization in action: combining multi-token fragments to activate abstract multilingual features.
And that is what we will look at next. What do these middle layer abstractions look like in practice?
Middle Layer abstractions
We can see, from the examples we just looked at, that LLMs initially identify simple, n-gram associations for the input tokens. This detokenization step enables the LLM to reconstruct local concepts from subword tokens, recognising for instance, that a sequence refers to the concept of “opposite” in terms of word meaning or that “order” is being used in conjunction with a restaurant scenario.
The key point to takeaway here is that the focus on these early layers is decidedly “local”.
It’s local two senses: first, the features activate narrowly around immediate surface-level patterns (like “order” appearing in familiar n-gram phrases such as “take my order” or “place your order”); second, the associations are highly specific — firing when a tight cluster of words or subwords frequently co-occur together.
This local pattern recognition lays the groundwork for deeper processing, but it is still fundamentally focused on tokens and short-term context, not on broader meaning or more abstract global context.
From tokens to topics: mid-layer abstractions
To build on these basic features the middle layers focus on a higher level of abstraction.
As we will see, some of the example features uncovered by Anthropic show how the middle layers focus on “global” context, not just matching specific words, but recognizing broader situations or scenarios.
Instead of narrowly activating on the token “order” a mid-layer feature might fire on a more general concept of a family meal, a celebration event or a restaurant experience.
The first example we will look at shows how middle layer features can capture broad topics like trade and commerce, abstracting far beyond any single token or phrase.
Buying, Selling, and Salt
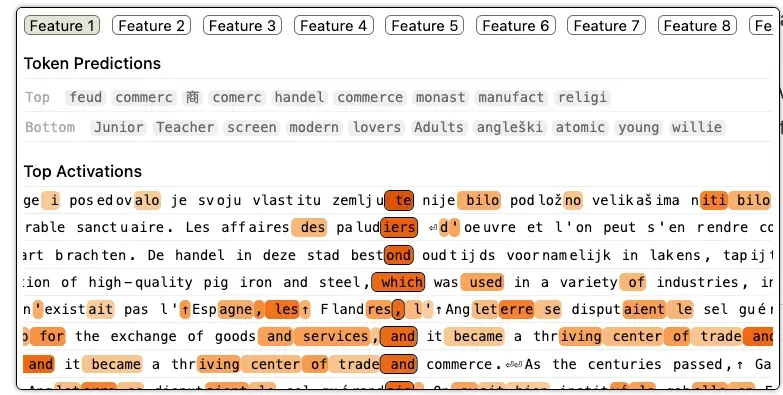
The first thing to note about the above example is that it activates across multiple languages. Already it is operating on a higher level of abstraction than a simple n-gram type frequency matcher. There appears to be French, Dutch and English sentences, amongst others, which are activated.
The next thing to notice is that it’s no longer as simple to identify the feature based on obvious keywords. This feature seems related to commerce, but it does not simply fire on sentences containing the word “commerce”. Instead it seems to be active on:
- Centres of trade and commerce
- Places where goods and services are exchanged
- Goods that are used in a variety of industries
- History or trade in a city (the sentence “De handel in deze …” seems to be Dutch for “The trade in this city in ancient times was mainly in cloth”)
- Salt workers (the phrase “Les affaires des paludiers” seems to be French for “The salt workers' business”)
This feature is no longer focused just on local contexts like “commerce” or “trade” as tokens. It is beginning to identify larger semantic structures - the broader idea of where and how trade occurs, and what kinds of goods or services are involved..
We can think of this as the early emergence of an economic concept feature. As training continues, this concept might split into more specialized sub-features:
- Trade during specific historical periods
- Goods trade vs. services trade
- Domestic vs. international trade
- Economic measures like GDP, trade balances, or business cycles
Some of the top activations for this feature - partial tokens like "commerc", "monast", "manufact", and "relig" - hint at these broader historical and economic associations.
Understanding these mid-layer features is critical for prompting. Without realizing it, a prompt mentioning "trade" might accidentally nudge the model toward a historical or physical-goods interpretation, when the user intended something more financial, like currency fluctuations or stock markets.
Recognizing the structure of these mid-layer abstractions helps explain why models sometimes seem to misinterpret prompts and gives us clues for crafting better ones.
Where Are We Going?

Feature 25 from Anthropics 50 samples for the middle layer provides another good example of an abstraction feature. Take a moment to look at the activations — what do you think this feature might be referring to?
While it is difficult to be certain, it appears to fire in contexts related to directionality and spatial relationships. We see there are activations on words like:
- Vertically
- Laterally
- Rearwardly
- Upwards (from the German aufWärts)
- Direction of the insert
More specifically, it seems tied to descriptions of motion, orientation and positioning in physical space. The model seems to be building a representation of spatial structure which recognizes when the text describes movement, relative location and flow.
As with our previous example about commerce, this feature is not simply directing a single direction word like “up” or “down”. Instead, it abstracts across many different directional terms to recognize a general situation: “this text is describing spatial motion or arrangement”.
This shows how mid-layer features move beyond isolated word matches to build unified, high-level representations. In this case, linking words like “vertically”, “laterally” and “rearwardly” into a coherent semantic frame of physical space and movement.
The mode is no longer just detecting directions, instead it’s recognizing when the world is moving.
Have You Tried Turning It Off?

The previous features we looked at represented abstract features related to trade and commerce and directionality and spatial motion. The last mid-level feature we will look at is another good example of how a higher level abstraction is different from the simple, n-gram similarity of the early layers.
Initially, it might not be very clear what feature is being represented here. Looking more closely you can see that the activations seem related to phrases like:
- Code and traceback
- Location of log files (logs2.tgz)
- Audio playback
- Screenshots of errors
- Syslog extract of the bug
This indicates that the general concept being represented here is related to the reporting of technical errors. Specifically, it seems to fire when the input is related to different ways a customer or user might submit bug reports or errors. In this light, the feature may represent a customer service scenario where a customer is reporting problems with a product or service.
Again, what is interesting is there is no narrow activation on words like “errors” or “screenshot” or “logs”. Instead it is a general concept where activations relate to the different ways and mediums people might use to report an error.
The range of this feature seems particularly wide. From a conceptual point of view we could claim that it is a broad concept related to software debugging. This had benefits but one potential disadvantage might be that the feature could be activated for unintended context. For example, a prompt might include a reference to a printout or output from stackoverflow and the LLM may incorrectly represent this as the reporting of an error or a bug. If the concept is too “fuzzy” it might fire for too many contexts and make it difficult to accurately steer the LLM to where you intended.
Practical takeaways for your prompts?
We’ve only scratched the surface of Anthropic’s recent research, looking at just a handful of the features they surfaced from early and middle layers of the Haiku model. But even this small sample gives us useful insights into how detokenization and abstraction shape the way LLMs process our inputs and what that means for prompt design.
Tokenization is not semantic - but we act as if it is
Tokenizers break words into smaller fragments to reduce vocabulary size, not to preserve meaning. They compress input into a more efficient representational form which often results in token splits that make intuitive concepts harder for the model to interpret directly.
For example:
“I want you to act like the Eiffel Tower…”
We assume the model will instantly understand this as referencing a famous monument in Paris. But it might see something like ['E', '##iff', '##el', 'Tower'] as a set of fragments which it must first reconstruct into a coherent unit before linking it to what it knows about the Eiffel Tower. This step may delay or distort semantic activation if the phrase is uncommon or appears in unexpected tokenized forms.
In most cases, the model handles this well but when the phrase is rare, or the prompt is already complex, this extra work can lead to confusion or drift.
What to do:
Check how your prompt is tokenized, especially critical names, technical terms, or low-frequency phrases. If important concepts are fragmented, reinforce them with context and clarification. Make it easier for the model to “see” the meaning you intend.
Think in clusters, not keywords
Middle-layer features don’t fire on single words, instead they activate on clusters of related tokens that point toward a shared concept. You saw this in the "trade and commerce" example — activations didn’t just occur on the word “trade,” but across a range of semantically related tokens about goods, markets, and locations.
Anthropic describes these fuzzy groupings as supernodes6:
So if you're aiming to activate a concept like ordering food, don’t just say “order.” Add related cues like "menu," "restaurant," "waiter," or "takeout." The more pieces of the puzzle you include, the more likely you’ll trigger the right conceptual region. You want to steer the model away from the other concepts of order such as:
- military structures
- filing systems
- taxonomic classification
- or even the act of issuing commands
What to do:
Treat your prompt like a semantic spotlight. Include multiple related words or ideas to reinforce the broader concept especially when disambiguation matters.
Expect fuzziness and design for robustness
We saw that tokenization can be cumbersome and may not encode the words you care about a single tokens. Even if your prompt is tokenized cleanly, middle-layer abstractions are noisy and broad. Features overlap. Supernodes aren’t clearly defined - even Anthropic notes that:
In other words: the internal representations are approximate, not cleanly scoped. This means your prompt may activate neighbouring but unintended concepts, especially in ambiguous domains.
What to do:
Design prompts that over-specify when necessary. Instead of:
“Act like the Eiffel Tower,”
try:
“Act like the Eiffel Tower, the famous monument in Paris that tourists visit.”
This way, even if the model wobbles a little in its internal abstractions, your context gives it the best chance of landing close to your intent.
Behind every clear output is a messy journey through layers of fragments, features, and fuzzy concepts. The better you understand that journey, the better your prompts can guide it.
References
1. Anthropic (2025). The Biology of Large Language Models .
2. Anthropic (2021). A Mathematical Framework for Transformer Circuits .
3. Gurnee, W., et al. (2023). Finding Neurons in a Haystack: Case Studies with Sparse Probing .
4. Gurnee, W., et al. (2023). Finding Neurons in a Haystack: Case Studies with Sparse Probing , Appendix A.14.
5. Gurnee, W., et al. (2023). Finding Neurons in a Haystack: Case Studies with Sparse Probing , Section 5.1.
6. Anthropic (2025). “Similar features and supernodes” , in The Biology of Large Language Models.
An earlier version of this essay was originally published on Substack .


